Generating Image Descriptions via Sequential Cross-Modal Alignment Guided by Human Gaze
Generating Image Descriptions via Sequential Cross-Modal Alignment Guided by Human Gaze
Abstract
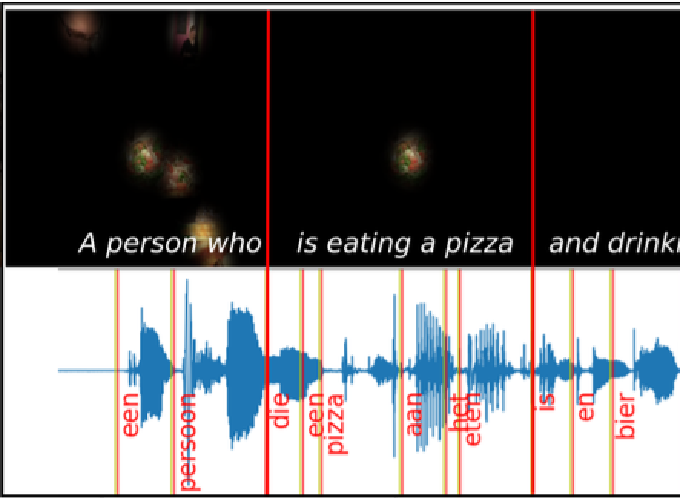
When speakers describe an image, they tend to look at objects before mentioning them. In this paper, we investigate such sequential cross-modal alignment by modelling the image description generation process computationally. We take as our starting point a state-of-the-art image captioning system and develop several model variants that exploit information from human gaze patterns recorded during language production. In particular, we propose the first approach to image description generation where visual processing is modelled sequentially. Our experiments and analyses confirm that exploiting gaze-driven attention enhances image captioning. Furthermore, processing gaze data sequentially leads to descriptions that are better aligned to those produced by speakers, more diverse, and more natural—particularly when gaze is encoded with a dedicated recurrent component.