Blackbox Meets Blackbox: Representational Similarity and Stability Analysis of Neural Language Models and Brains
Blackbox Meets Blackbox: Representational Similarity and Stability Analysis of Neural Language Models and Brains
Abstract
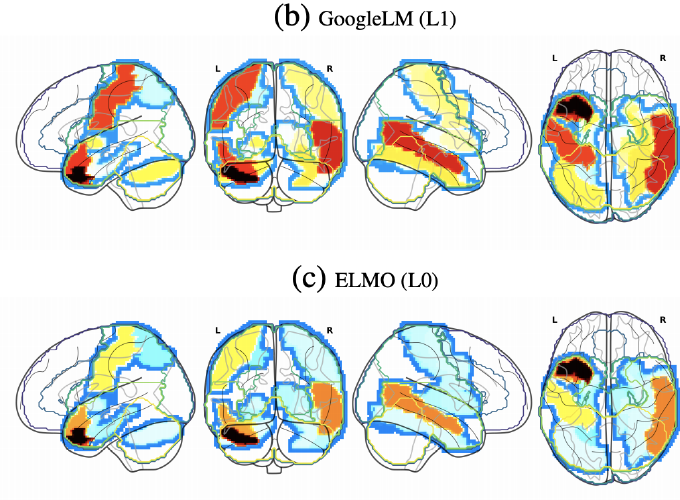
In this paper, we define and apply representational stability analysis (ReStA), an intuitive way of analyzing neural language models. ReStA is a variant of the popular representational similarity analysis (RSA) in cognitive neuroscience. While RSA can be used to compare representations in models, model components, and human brains, ReStA compares instances of the same model, while systematically varying single model parameter. Using ReStA, we study four recent and successful neural language models, and evaluate how sensitive their internal representations are to the amount of prior context. Using RSA, we perform a systematic study of how similar the representational spaces in the first and second (or higher) layers of these models are to each other and to patterns of activation in the human brain. Our results reveal surprisingly strong differences between language models, and give insights into where the deep linguistic processing, that integrates information over multiple sentences, is happening in these models. The combination of ReStA and RSA on models and brains allows us to start addressing the important question of what kind of linguistic processes we can hope to observe in fMRI brain imaging data. In particular, our results suggest that the data on story reading from Wehbe et al. (2014) contains a signal of shallow linguistic processing, but show no evidence on the more interesting deep linguistic processing.